知识图谱类产品信息处理技术构想
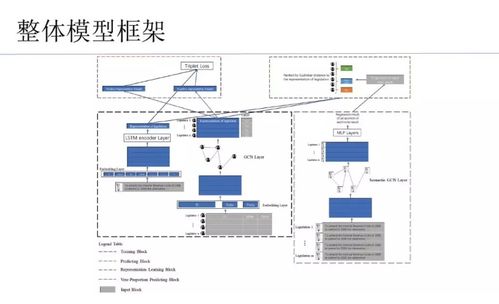
在知识图谱类产品的开发中,信息处理作为关键环节,其质量直接决定了知识图谱的准确性与应用价值。以下是针对信息处理模块的开题构想,涵盖数据采集、信息抽取与数据整合三大核心部分。
- 数据采集与预处理
- 数据来源:整合结构化数据(如数据库、表格)、半结构化数据(如XML、JSON文档)和非结构化数据(如文本、网页、多媒体)。
- 预处理策略:实施数据清洗,去除噪声与冗余;采用数据规范化技术,统一格式与编码;对多源数据进行对齐与融合,以消除冲突。
- 信息抽取与构建
- 实体识别:利用自然语言处理技术,自动识别文本中的实体(如人物、地点、事件),并结合上下文进行消歧。
- 关系抽取:通过规则引擎、机器学习或深度学习模型,提取实体间的语义关系(如“属于”、“位于”),并构建关系三元组。
- 属性抽取:从数据中抽取实体的关键属性(如人物的出生日期、地点的经纬度),丰富知识图谱的细节。
- 数据整合与质量控制
- 知识融合:将抽取的实体、关系和属性进行跨源整合,解决重叠与冲突问题,确保知识一致性。
- 质量评估:引入人工审核与自动化验证机制,对信息抽取结果进行准确性、完整性和时效性评估,并建立反馈循环以持续优化。
总体而言,信息处理模块旨在构建高质量、可扩展的知识基础,为后续的知识推理与应用提供可靠支撑。在实现过程中,需注重技术选型(如结合BERT、图神经网络等前沿方法)与实际场景的适配性,以提升产品的实用价值。
如若转载,请注明出处:http://www.jiayue118.com/product/33.html
更新时间:2025-11-29 21:00:03